|
I am currently a Research Engineer of (Meta) Reality Labs Research and was a former intern in Facebook AI Research (FAIR). Prior to that, I obtained the Ph.D. degree from The Chinese University of Hong Kong, Multimedia Laboratory, in September 2021. I received my B.E from computer science and technology department of Tsinghua University in 2016. My research interests include multimodal LLM, video generation, and 3D computer vision. Email / Github / Google Scholar / LinkedIn / CV |

|

|
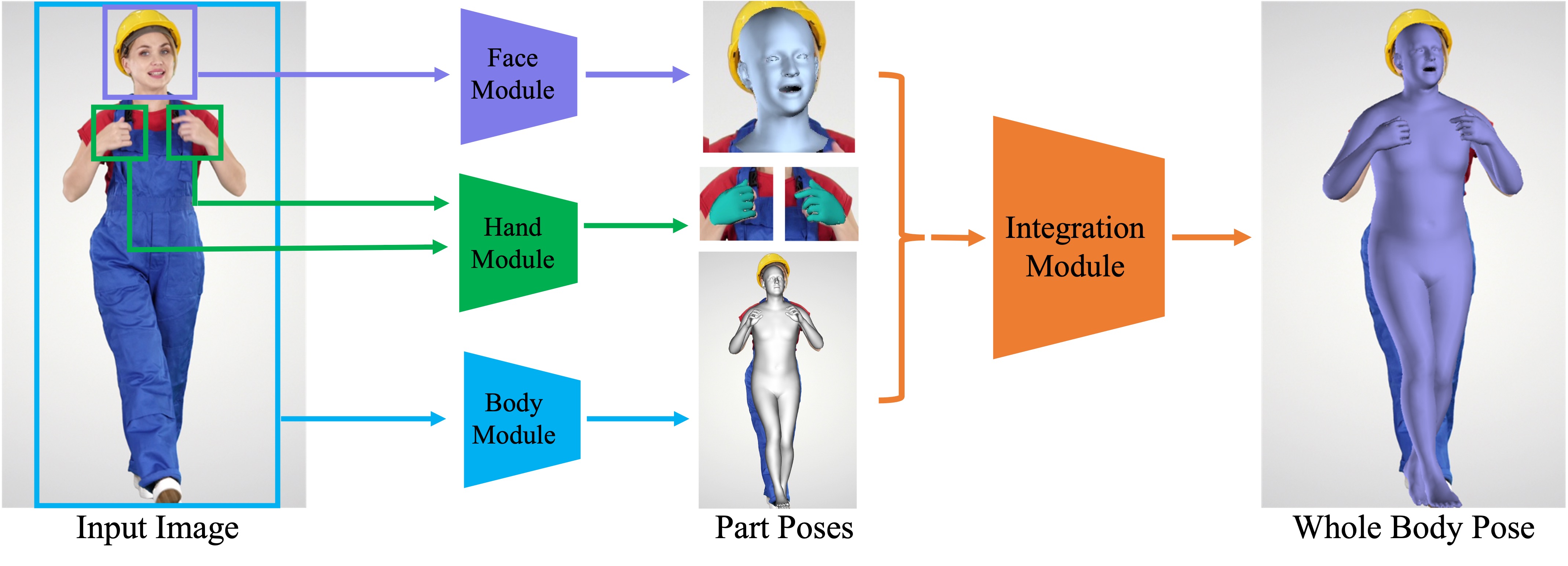
Mar. 2022 - Now, Reality Labs Research Research Engineer. Redmond, WA, U.S. Build human centric foundation model for processing large-scale images and videos. The model is built upon ViT backbone pretrained on billions images and post-trained with synthetic datasets. Additional prediction heads are added for estimating human motions and dense landmarks. The model is used to process millions videos which are used to train the foundational avatar model. |

|
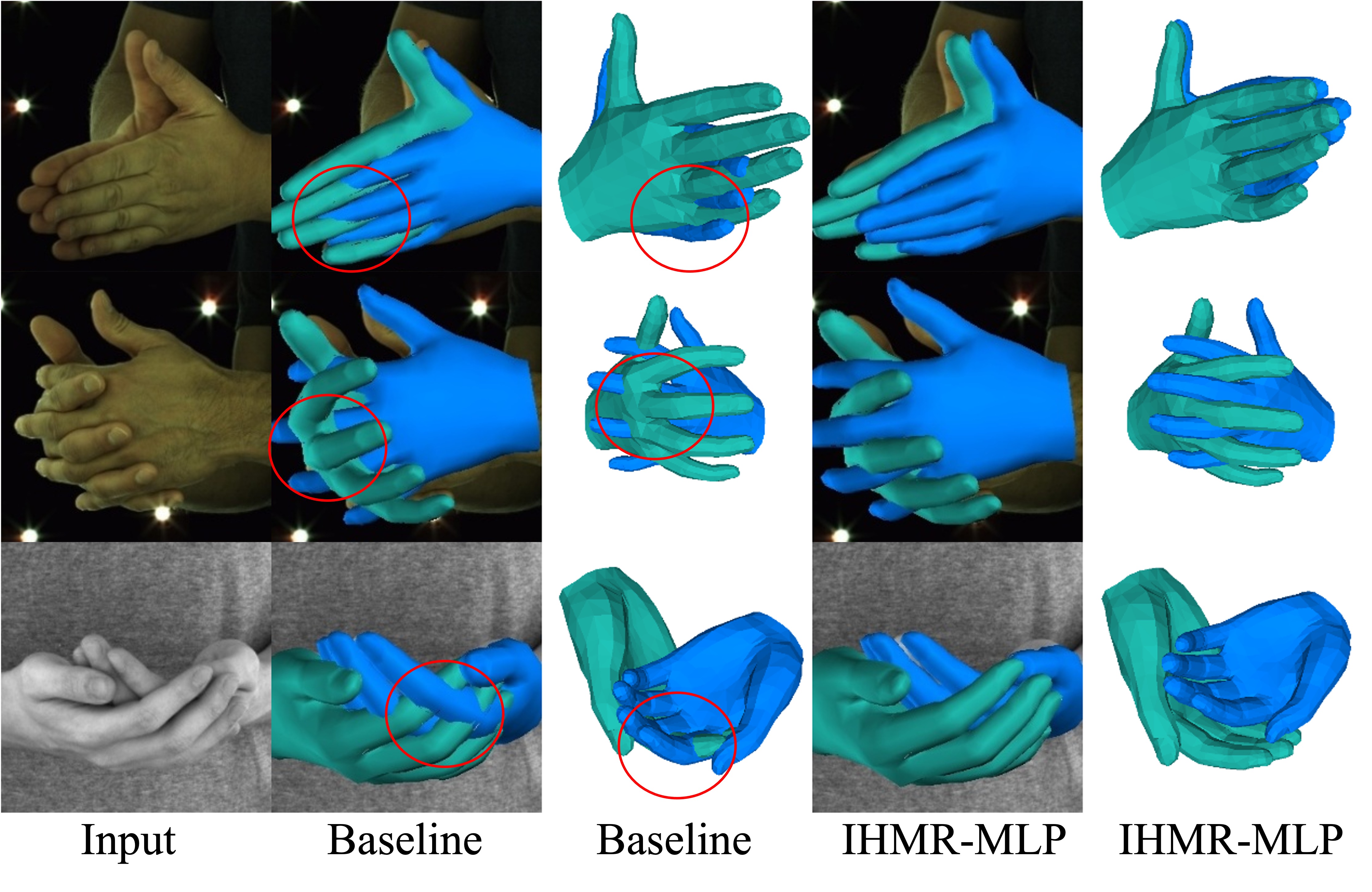
Jan. 2020 - May. 2020, Facebook AI Research (FAIR) Research Intern. Menlo Park, CA, U.S. We use SMPL-X to represent 3D hands and bodies and adopt separate modules for predicting independent hand and body motion first. Hand and body motion predictions are then combined and finetuned to get unified hand and body motion results. Our model runs 10x faster than previous methods with better performance on challenging in-the-wild scenarios with motion blur. |

|
July. 2017 - September 2021, The Chinese Unviersity of Hong Kong |

|
Aug. 2012 - Jul. 2016 , Tsinghua University |

|
|

|
|
|
|
|
|
|
|
|
|
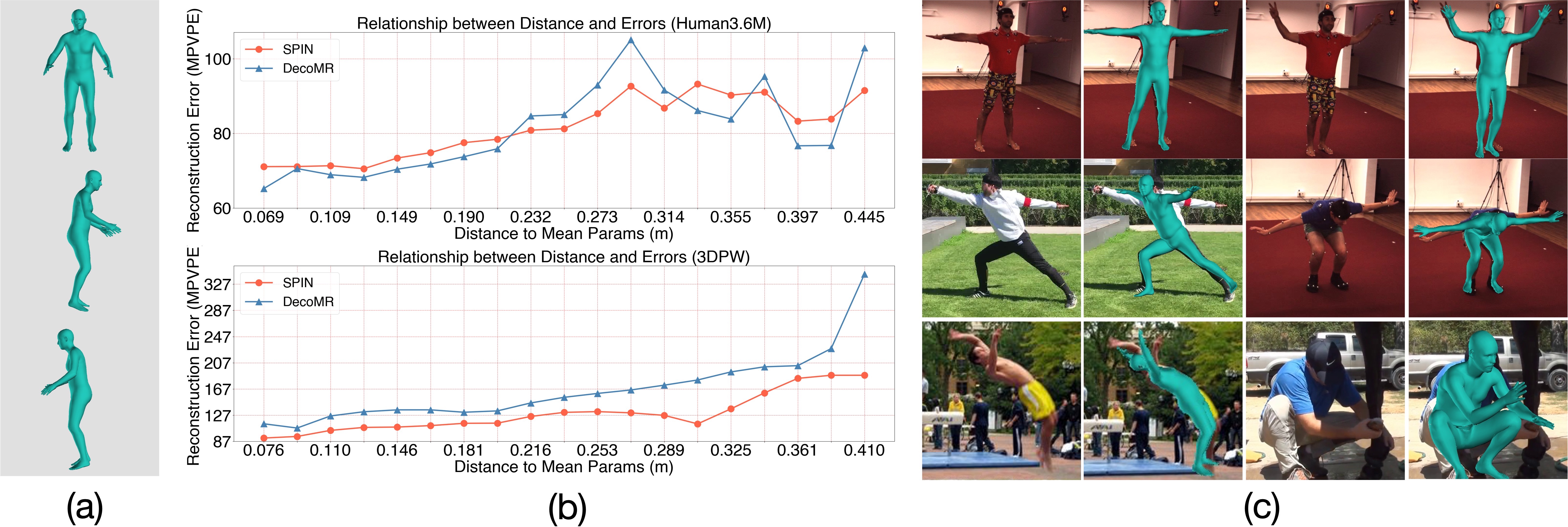
|
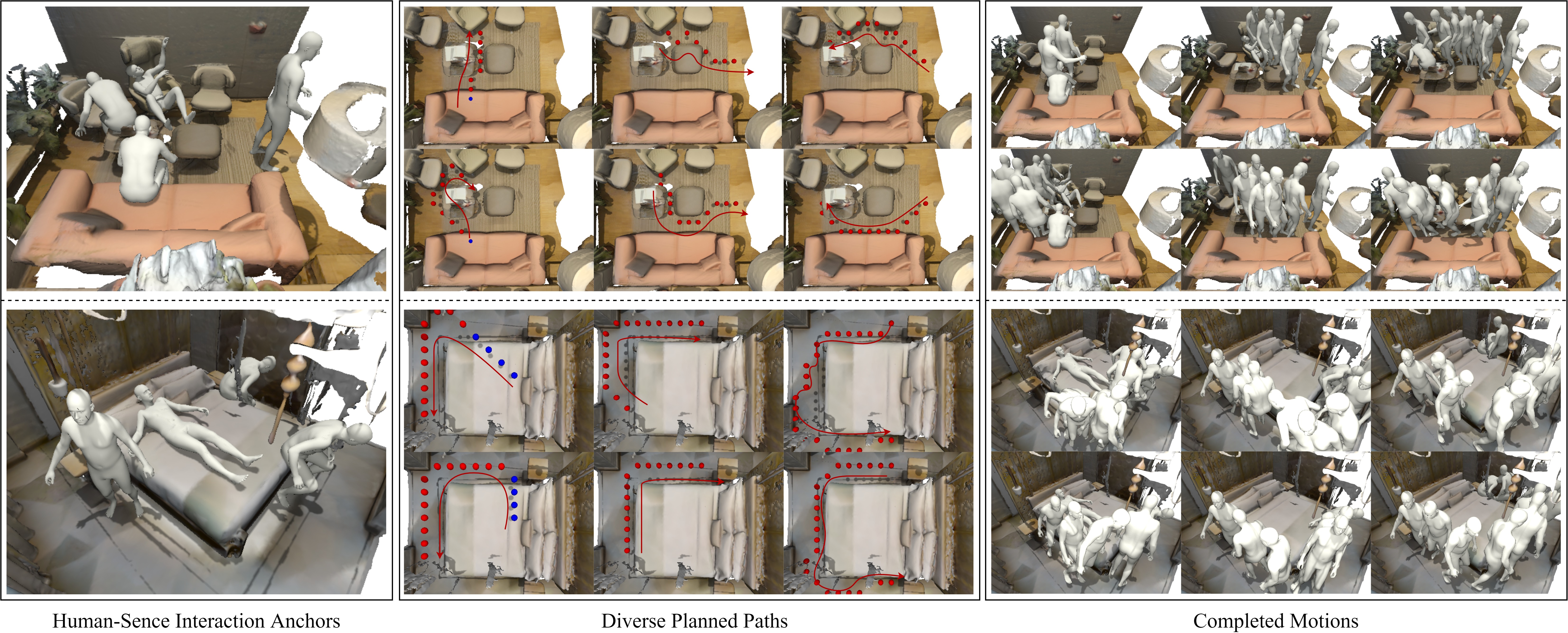
We design a novel framework to increase the 3D human mocap accuracy for challenging poses. |
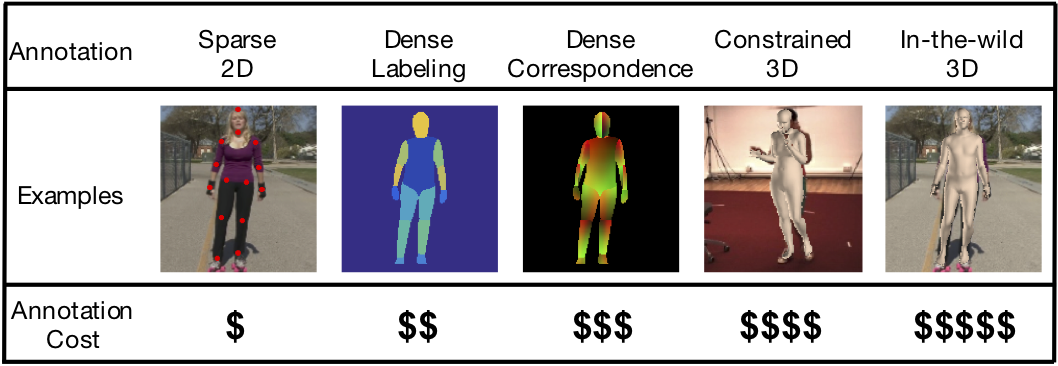
|
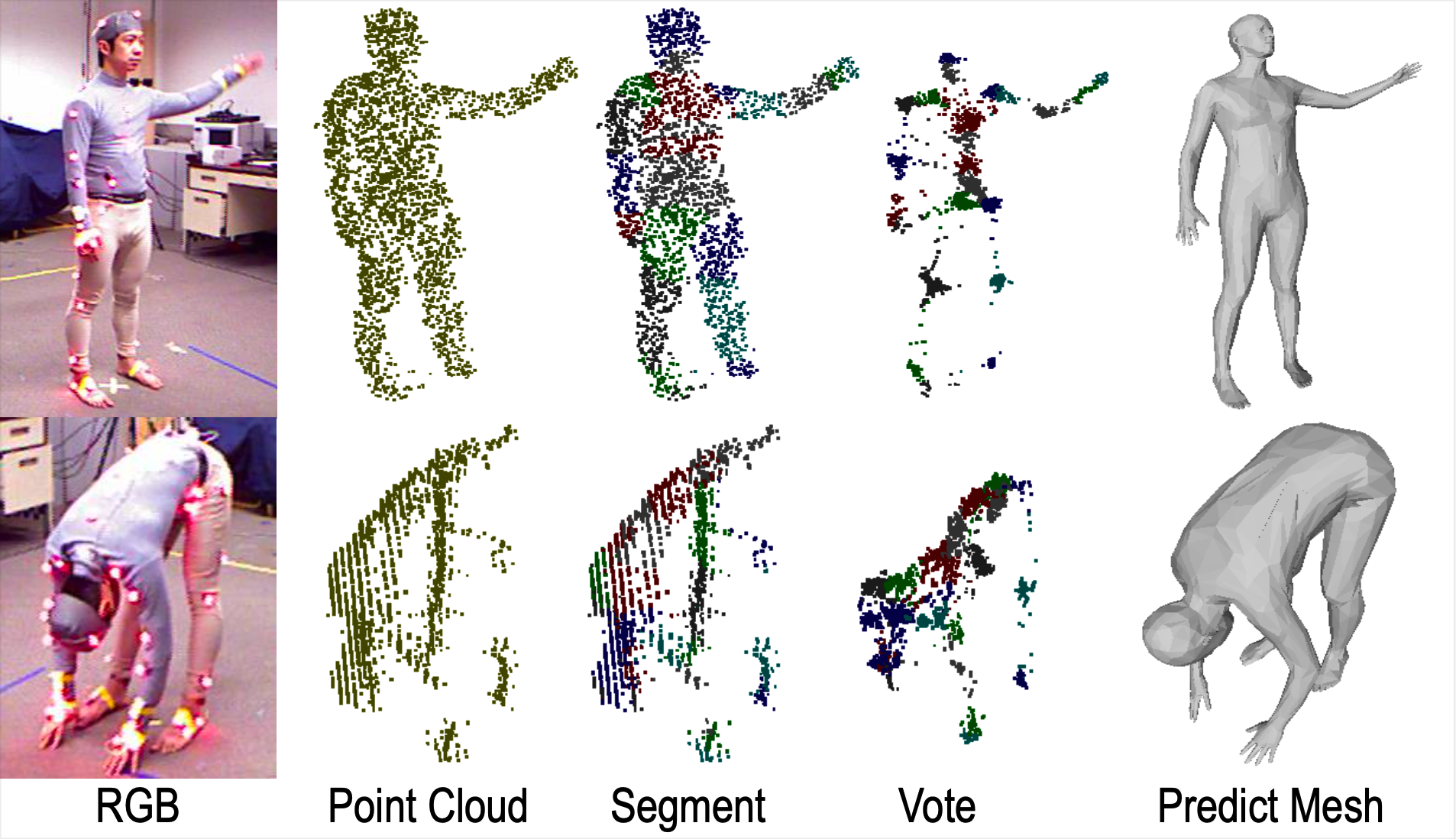
We provided sufficient investigation of annotation design for in-the-wild 3D human reconstruction. |
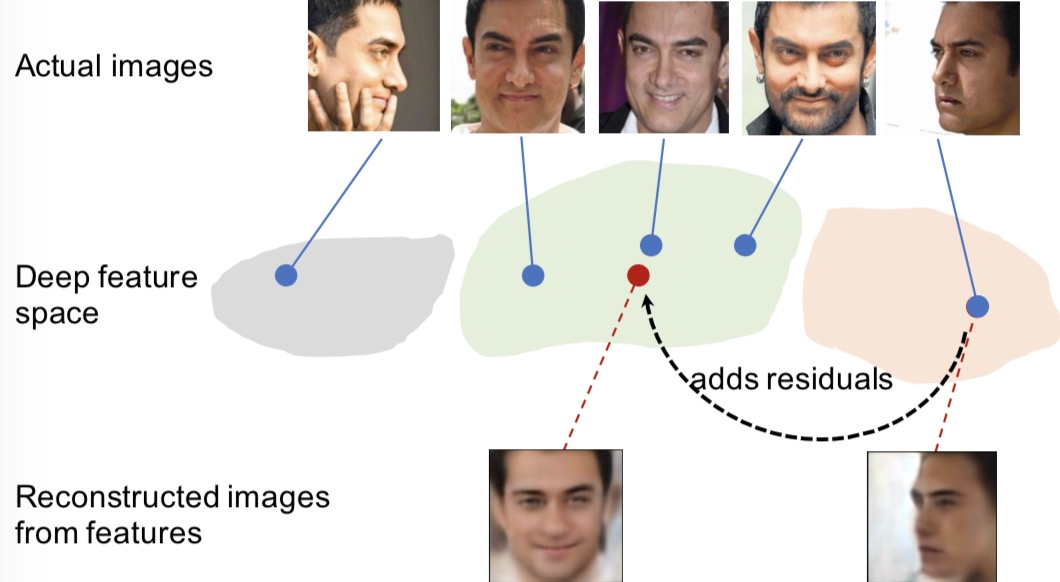
|
We presented a Deep Residual EquivAriant Mapping (DREAM) block to improve the performance of face recognition on profile faces. |
|
|