Monocular 3D Reconstruction of Interacting Hands via Collision-Aware Factorized Refinements
Abstract
3D interacting hand reconstruction is essential to facilitate human-machine interaction and human behaviors understanding. Previous works in this field either rely on auxiliary inputs such as depth images or they can only handle a single hand if monocular single RGB images are used. Single-hand methods tend to generate collided hand meshes, when applied to closely interacting hands, since they cannot model the interactions between two hands explicitly. In this paper, we make the first attempt to reconstruct 3D interacting hands from monocular single RGB images. Our method can generate 3D hand meshes with both precise 3D poses and minimal collisions. This is made possible via a two-stage framework. Specifically, the first stage adopts a convolutional neural network to generate coarse predictions that tolerate collisions but encourage pose-accurate hand meshes. The second stage progressively ameliorates the collisions through a series of factorized refinements while retaining the preciseness of 3D poses. We carefully investigate potential implementations for the factorized refinement, considering the trade-off between efficiency and accuracy. Extensive quantitative and qualitative results on large-scale datasets such as InterHand2.6M demonstrate the effectiveness of the proposed approach.
Framework
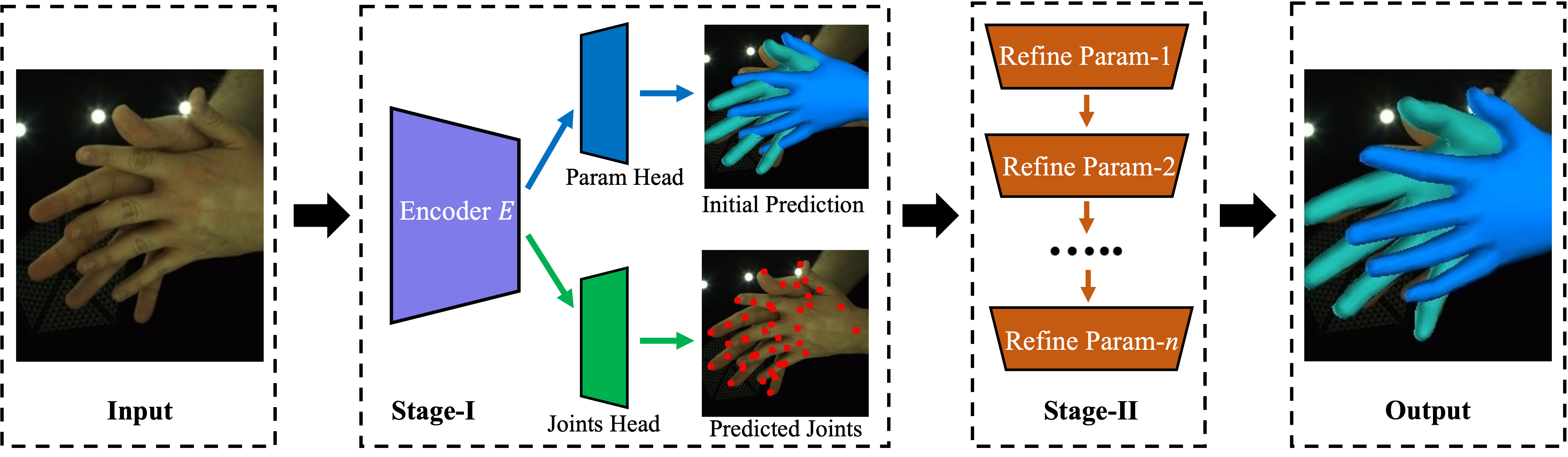
The proposed IHMR takes monocular RGB images as input and generates the 3D meshes represented in MANO. The framework has two stages. The first stage adopts a convolutional neural network composed of an encoder, a MANO parameter prediction head, and a 2D/3D joint prediction head. It outputs the initial predicted parameters and predicted 2D and 3D joints. By taking initial predictions as input, the second stage performs factorized refinement to gradually remove the collisions from the first stage and produce refined predictions.
Experimental Results
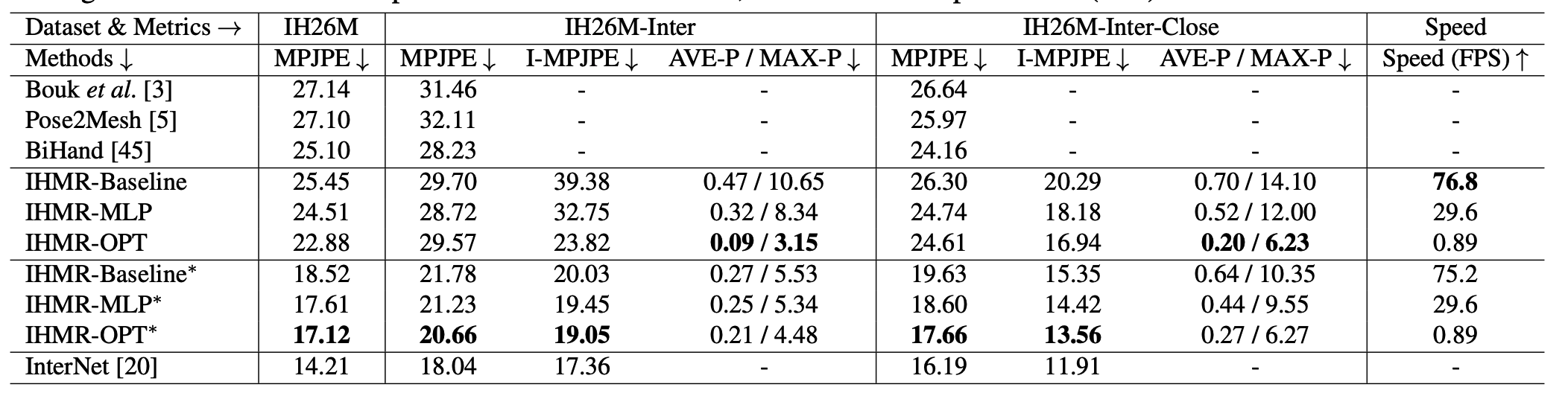
We compare with previous methods on InterHand2.6M. The metrics are MPJPE (separately calculated for each hand), I-MPJPE (considering two hands together, with scale and translation aligned with GT), AVE-P (average penetration between two hands), and MAX-P (maximum penetration between two hands). We evaluate models on both the whole evaluation set and the subsets composed of interacting and closely interacting samples.

Materials



Citation
@InProceedings{rong2021ihmr,
author = {Rong, Yu and Wang, Jingbo and Liu, Ziwei and Loy, Chen Change},
title = {Monocular 3D Reconstruction of Interacting Handsvia Collision-Aware Factorized Refinements},
booktitle = {International Conference on 3D Vision},
year = {2021}
}