Chasing the Tail in Monocular 3D Human Reconstruction with Prototype Memory
Abstract
Deep neural networks have achieved remarkable progress in single-image 3D human reconstruction. However, existing methods still fall short in predicting rare poses. The reason is that most of the current models perform regression based on a single human prototype, which is similar to common poses while far from the rare poses. In this work, we 1) identify and analyze this learning obstacle and 2) propose a prototype memory-augmented network, \methodname, that effectively improves performances of predicting rare poses. The core of our framework is a memory module that learns and stores a set of 3D human prototypes capturing local distributions for either common poses or rare poses. With this formulation, the regression starts from a better initialization, which is relatively easier to converge. Extensive experiments on several widely employed datasets demonstrate the proposed framework's effectiveness compared to other state-of-the-art methods. Notably, our approach significantly improves the models' performances on rare poses while generating comparable results on other samples.
Motivation
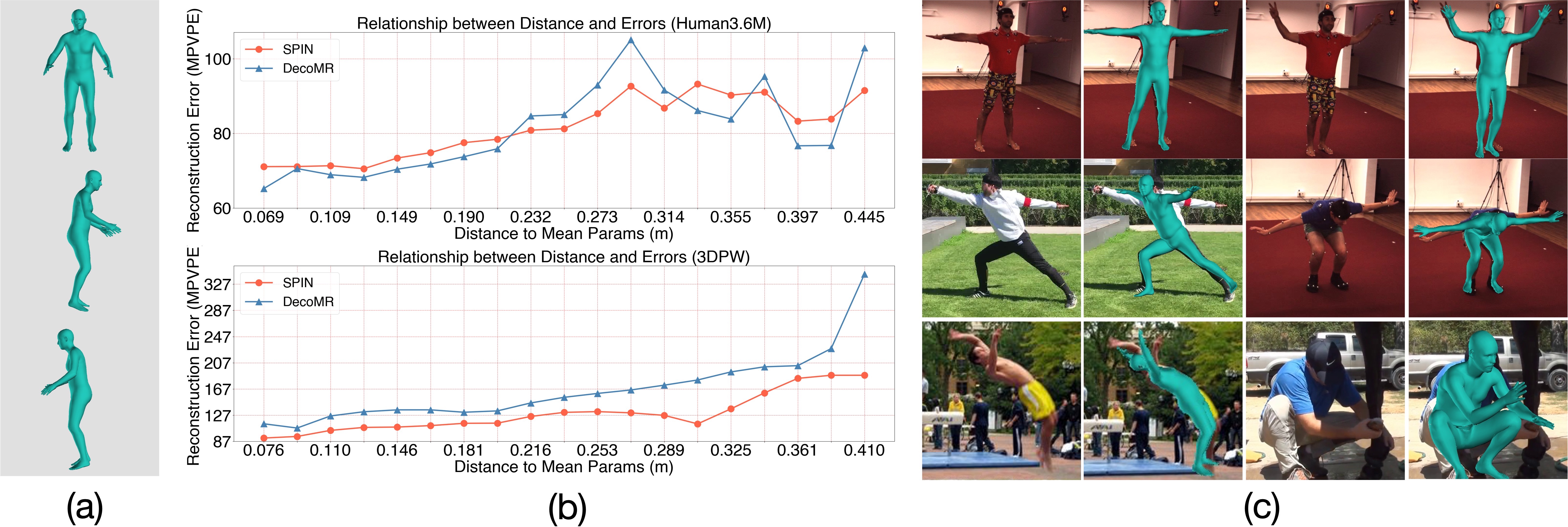
In (a), we show one typical singular human prototype used by previous works (i.e. SPIN). In (b), we plot the relationship between the samples' distances to the mean parameters and models' reconstruction error (mean per-vertex position error) on the two widely used evaluation sets, ~\ie the evaluation sets of Human3.6M and 3DPW. We select two state-of-the-art 3D human reconstruction models, namely SPIN and DecoMR. In (c), we show several typical examples with gradually increasing distances to the human prototype depicted in (a). As the figure shows, the model (SPIN) generates less precise results on samples with larger distances.
Framework
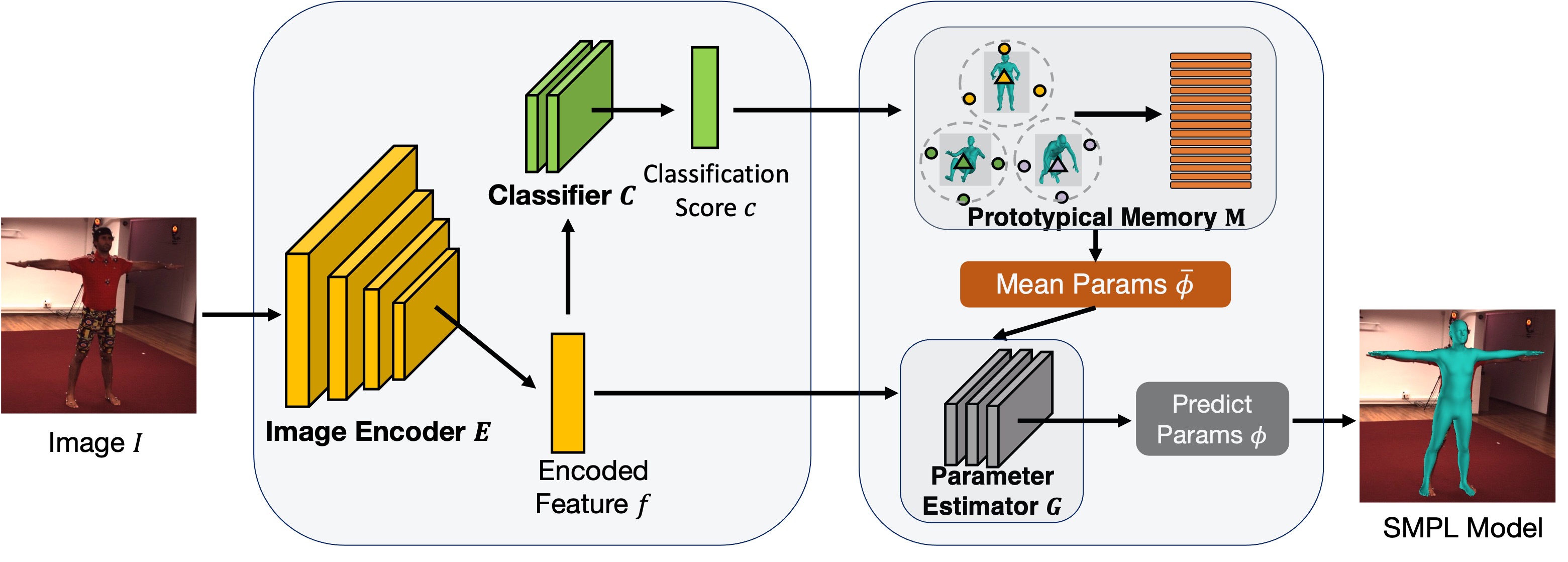
The proposed IHMR takes monocular RGB images as input and generates the 3D meshes represented in MANO. The framework has two stages. The first stage adopts a convolutional neural network composed of an encoder, a MANO parameter prediction head, and a 2D/3D joint prediction head. It outputs the initial predicted parameters and predicted 2D and 3D joints. By taking initial predictions as input, the second stage performs factorized refinement to gradually remove the collisions from the first stage and produce refined predictions.
Experimental Results
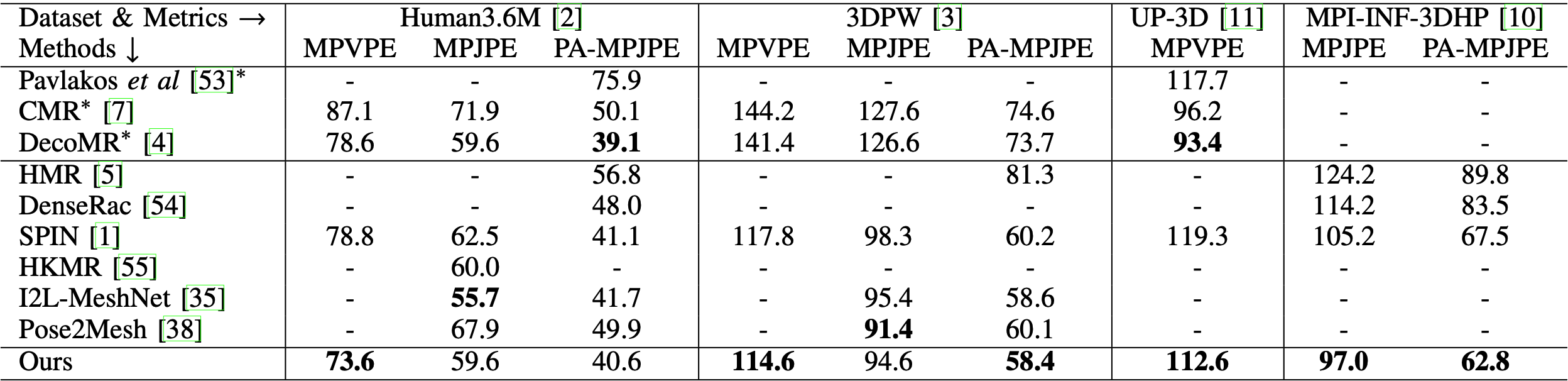
We compare the proposed PM-Net with previous state-of-the-art methods on several widely used dataset including Human3.6M, 3DPW, UP-3D, and MPI-INF-3DHP. All metrics use millimeters (mm) as the unit and are the lower the better. We use MPVPE, MPJPE, and PA-MPJPE as the evaluation metrics. We mark the methods that use UP-3D in training with *.


Citation
@Article{rong2021chasing,
author = {Rong, Yu and Liu, Ziwei and Loy, Chen Change},
title = {Chasing the Tail in Monocular 3D Human Reconstruction with Prototype Memory},
booktitle = {IEEE Transactions on Image Processing},
year = {2022}
}